In this guide, I will explain both data quality (DQ) and the six data quality dimensions. Additionally, you will learn advanced data quality concepts, data quality measurement, and examples of different data quality dimensions. This guide shares my 25+ years of experience in real data engineering. Let’s dive right in.
Data quality (DQ) is defined as the data’s suitability for a user’s defined purpose. It is subjective, as the concept of quality is relative to the standards defined by the end users’ expectations.
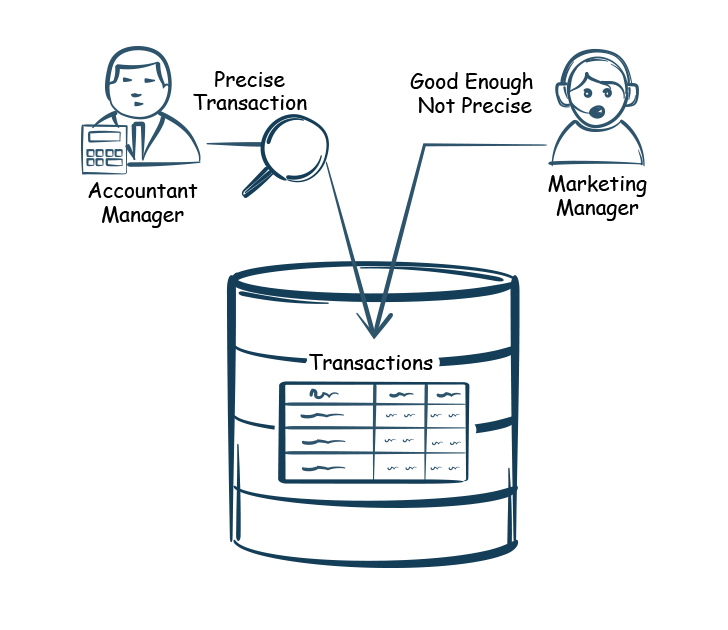
| Data Quality Expectations: It is possible that for the exact same data, depending on their usage, different users can have totally different data quality expectations. For example, the accounting department needs accurate data to the penny, whereas the marketing team does not, because the approximate sales number are enough to determine the sales trends. |
|
| Data Quality Expectations: It is possible that for the exact same data, depending on their usage, different users can have totally different data quality expectations. For example, the accounting department needs accurate data to the penny, whereas the marketing team does, because the approximate sales number are enough to determine the sales trends. |
Instead of just providing definitions of different data quality dimensions, this guide provides a comprehensive and very nuanced list of use cases and examples from our professional experience.
The six data quality dimensions are Accuracy, Completeness, Consistency, Uniqueness, Timeliness, and Validity. However, this classification is not universally agreed upon.
In this guide we have added four more – Currency, Conformity, Integrity, and Precision – to create a total of 10 DQ dimensions.
We by nature, like to classify things. For example, we classify animals into various categories such as reptiles, mammals, birds, etc. Similarly, Data Quality dimensions are a superficial concept introduced to bucket data quality issues with similar patterns. You can of course choose to restrict, expand, or come up with your own taxonomy.
We by nature, like to classify things. For example, we classify animals into various categories such as reptiles, mammals, birds, etc. Similarly, Data Quality dimensions are a superficial concept introduced to bucket data quality issues with similar patterns. You can of course choose to restrict, expand, or come up with your own taxonomy.
Data accuracy is the degree to which data represent real-world things, events, or an agreed-upon source.
For example, if a prospective employee has an inaccurate interview address, he won’t be able to attend the interview until he obtains the accurate address.
We will take two examples explaining the data accuracy dimension and how it can be measured:
Example: We do this data accuracy check at the grocery store every time we do purchase by checking the items in the bill, then physically checking for the items in the grocery cart.
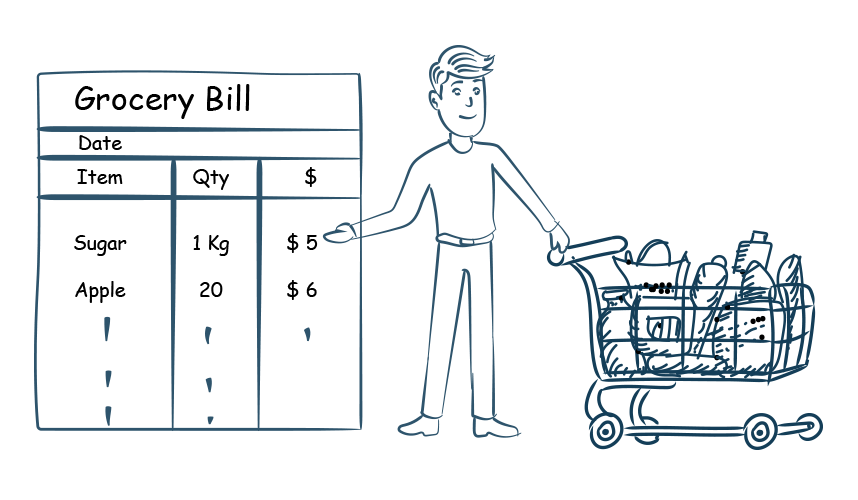 |
| Data accuracy can be judged by comparing the data values with a physical measurement or physical observations. |
Example: We do this data accuracy check at the grocery store every time we do purchase by checking the items in the bill, then physically checking for the items in the grocery cart.

Another way to measure accuracy is by simply comparing actual values to standard or reference values provided by a reliable source.
Example: The Consumer Price Index (CPI) is published by the US Bureau of Statistics.
If you have CPI index values in your database, then for the accuracy measurement, you can compare it with the reference values obtained from the US Bureau of Statistics website.
The completeness data quality dimension is defined as the percentage of data populated vs. the possibility of 100% fulfillment.
 |
| You have probably heard multiple times that the data is incomplete to take a decision. For example, a salesperson wants to send an email to the customer, but the data entry operator did not fill in the email address. Here it is not that the data was inaccurate, but the email attribute was left empty. When data is missing it directly impedes the operations of any organization. We will use four examples explaining different types of data completeness quality issues: |
 | You are an eligible voter, but at the voting booth, the record with your name is missing from the voter’s list. This is an example of a missing record for the completeness data quality dimension. |
|
| You are an eligible voter, but at the voting booth, the record with your name is missing from the voter’s list. This is an example of a missing record for the completeness data quality dimension. |
Even though you have all the customer records, some of the attributes in the customer records might be missing values. For example, each customer record must have a name, email address, and phone. However, the phone number or the email ID might be missing in some of the customer records.


A system might not have all the reference values required for the domain. For example, a banker is trying to update a customer account to a “Suspended” state. The banker expects three reference values.
1. Open
2. Closed
3. Suspended
But the reference table has only two domain values “Open” and “Close”. He cannot find the “Suspended” reference value in the data. This is a case of reference data completeness. This is a specific case of the prior example where complete records are missing.
Even if an attribute is populated with a data value, it is possible that the values got truncated while loading. This often happens if the ETL process variables are not correctly defined, or the target attribute is not large enough to capture the full length of the data values.

Consistent data can be explained as how close your data aligns or is in uniformity with another dataset or a reference dataset.
Here are few examples of Data Consistency DQ dimension:
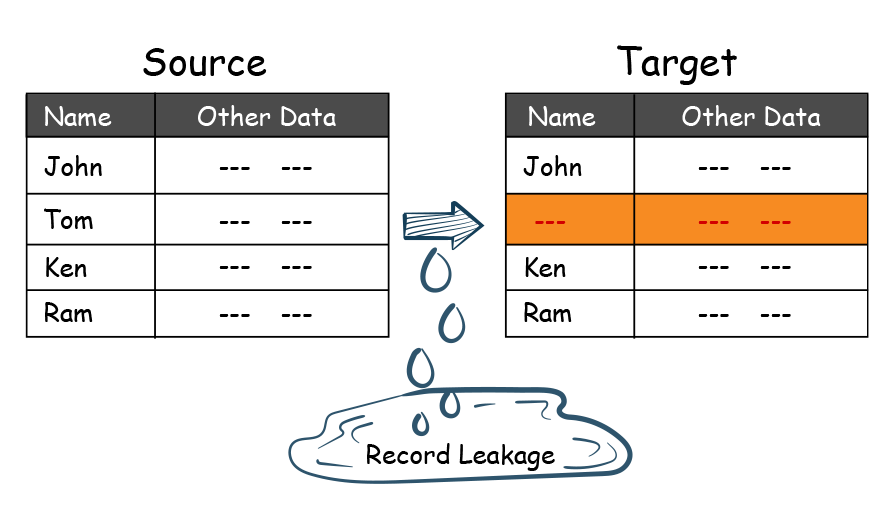
When data is loaded from one system to another, we need to ensure that the data reconciles with the source system. Source vs. target reconciliation usually get you the inconsistency in the records. Below is an example of inconsistency at the record level. The record for tom exists in the source but not in the target system.
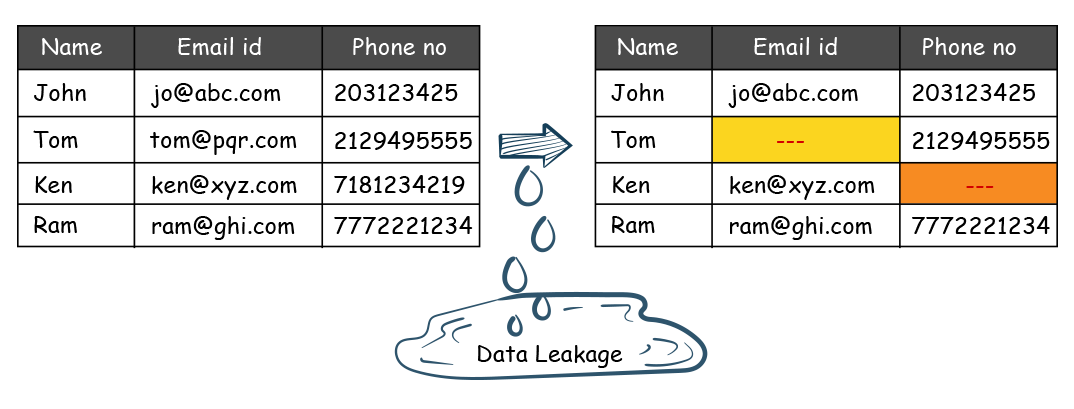
Another specialized example of inconsistency between source and target. The records exist on both sides, but their attributes do not match. In the case below record for Tom and Ken exists on both sides, but the target side is missing email for Tom’s record and Ken’s record is missing the phone number.
In a clothing store, a customer’s order shows an order for one gown and three dress pants. The shipping dataset for the same order shows that the store must ship three gowns and one dress pant. Here orders and shipment quantity are inconsistent between the two datasets.

A transaction is a collection of read/write operations succeeding only if all contained operations succeed. If the transaction is not executed properly then it can create consistency issues in the data.

The opening balance for account A500 was $9000, and $1000 was taken out. So, at the end of the day, the A500 account should have end of day balance of $8000, but it is showing as $4000. This happened because the transaction for some reason was not executed properly hence it has created inconsistency in the data.
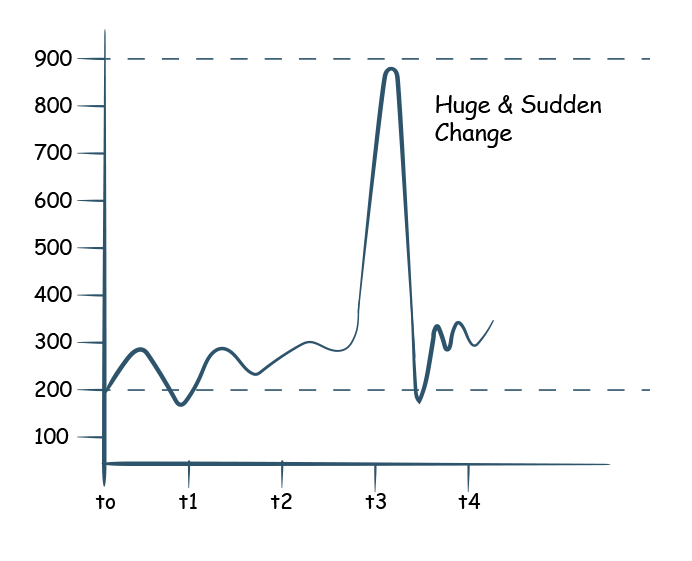
Data values and volumes are expected to be consistent over time with minor variations unless there is a big business change.
You receive IBM stock prices every day, suddenly you notice that the value has increased by 10 times. A 1000% increase in the stock price in a day is nearly impossible. This could be a simple mistake of misplacing the decimal.
Most companies acquire customers at a steady and consistent pace. If the business acquires about 500 new customers every day, and suddenly one day the number zooms to thousands, then there is a high possibility that the data was loaded twice because of some error. If the customer count suddenly drops to zero, then it is possible that the data processor has failed to run for that day.
The reference data is expected to be stored consistently not only in a dataset but also across multiple data stores. In a customer dataset, the reference table for sex has Male, Female, and Unknown.

Now this reference data might be used in multiple systems and for example the Return Material Authorization can have reference data consistency issues if
The occurrence of an object or an event gets recorded multiple times in a dataset.
An event or entity should only get recorded only once. No one wants duplicate data because it can cause double counting or create misreporting.

Below are the examples for duplicate data
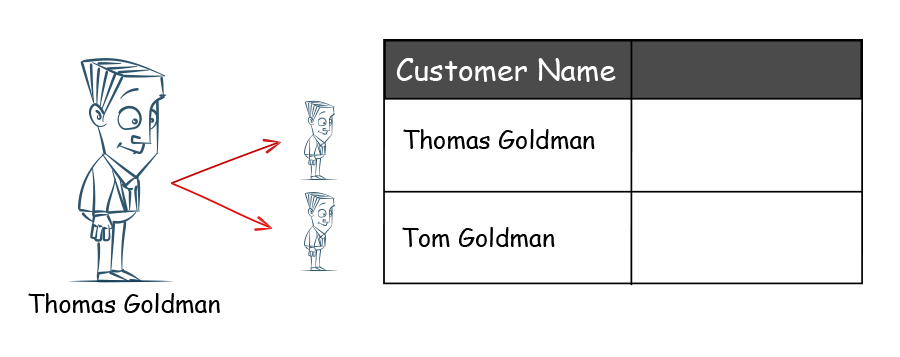
There is a general expectation that a single physical entity should be only represented once. In this example, the customer is recorded twice, initially as Thomas and second time by the nickname Tom. Someone accessing the data will be confused as to what to call the customer. Also, the information about the customer might be partially stored across the two records. The company will count the number of customers as two whereas there is only one customer.
If you simply check the data, you cannot determine if Thomas and Tom are the same because the names are different. You will need secondary but universally unique information such as emails to deduplicate such records.

In this case, the record identifier is exactly the same. The following case is easy to detect because the keys in the dataset can also be compared to themselves to find the duplicates.
Data validity describes the closeness of data value to predetermined values or a calculation.
 |
| Here are three examples of Validity DQ dimension |
The data captured in the datastore can be through a graphical user interface or some background ETL process. But, is the data valid according to the business rules? The business rule for Net Amount is Gross Amt – (Tax Amt + Fee Amt + Commission Amt).
The net amount can be validated by calculating the expected value based on the business rule.

The data values can also be based on ranges provided in advance. For example, the value (numeric or date) in an attribute must fall in the specified range.
Numeric Range: Weight range for a USPS parcel. If the weight data doesn’t match the parcel type, then we know the data is invalid.
| Parcel | Content must weigh less than 70 lbs. |
| Large Parcel | Contents must weigh less than 70 lbs. |
| Irregular Parcel | Contents must weigh less than 16 oz. |
 | Date Range: A liquor shop cannot have a customer who is less than 21 years old and rarely possible that the customer is older than 100 years. |
|
| Date Range: A liquor shop cannot have a customer who is less than 21 years old and rarely possible that the customer is older than 100 years. |
 | Normally you cannot ship without having the order in place. That is the business rule. So, if you find a shipping record that has a shipping date less than that of the order date, obviously there is a data validation problem. |
|
| Normally you cannot ship without having the order in place. That is the business rule. So, if you find a shipping record that has a shipping date less than that of the order date, obviously there is a data validation problem. |
It is the time lag between actual event time vs. the event captured in a system to make it available for use.
 |
| When an actual event occurs, the system needs to capture the event information, process it, and store it for further downstream usage. This is however never instantaneous. |
Here we are considering two timeliness data quality examples
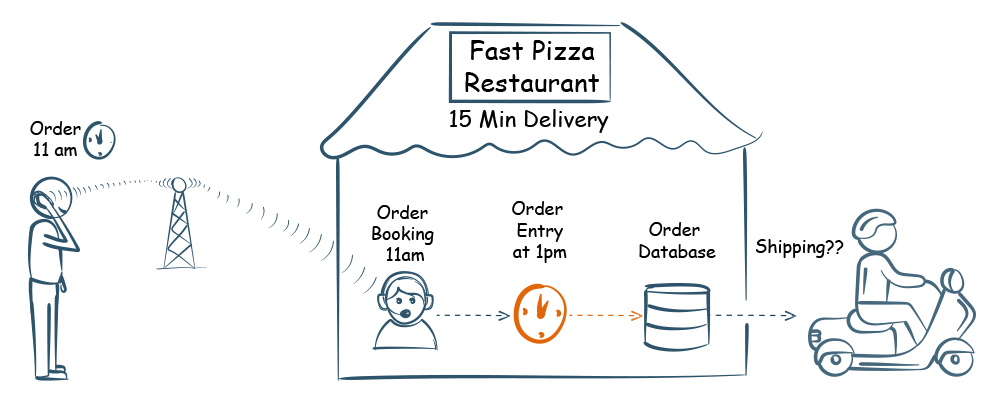 |
| A Pizza restaurant promises to deliver a pizza within 50 minutes. But the order booking clerk for some reason enters the data two hours late. In this case, the data is correct by themselves but for the business, it is too late. The pizza is delivered late which will result in negative reviews and probable loss of future business. It is due to not keeping their promise of timeliness. |
If there is a lag in the availability of data, their competitors will have an advantage over them. Again, even if the data is accurate, it still has poor timeliness quality.
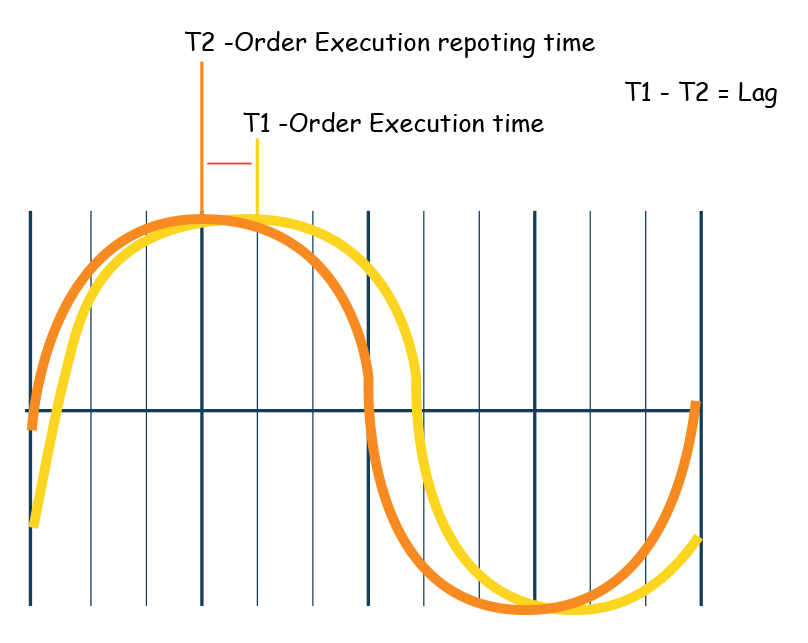 |
| In automated trading decisions to buy /sell, stocks are also taken in microseconds. The user excepts the immediate availability of data for its algorithmic trading. |
If there is a lag in the availability of data, their competitors will have an advantage over them. Again, even if the data is accurate, it still has poor timeliness quality.
Data Currency is about the reflection of the real-world state vs. the state captured in the dataset.
Many times the data captured contains the current state of an entity. The state of the object can change over time. If the state transition is not captured correctly the data becomes useless.
Here are two examples where the data currency DQ dimension:
 | A mailing list has customers’ addresses. But if the customers have already moved to a new address the data loses its currency. |
|
| A mailing list has customers’ addresses. But if the customers have already moved to a new address the data loses its currency. |
 |
| If you are trying to sell a wedding gown to your customer and sent a discount coupon as an incentive for purchase. The coupon was sent because the data showed the customer is unmarried and is in the market for a wedding dress. But the customer is already married. |
Timeliness is the late arrival of data or delay, but the information is still accurate. If the data is late and reflects a state that has changed, or expired, and hence the data became irrelevant and lost its value or currency.
Conformity means that the data values of the same attributes must be represented in a uniform format and data types.
 |
| Humans have a unique ability to discern subtle differences and understand the commonality. However, computers cannot. Even though the values may be correct but if the data does not have the same data standard format or data type then the data has conformity data quality issues. |
Below are two examples of data conformity:
Conformity means that the data values of the same attributes must be represented in a uniform format and data types.
Below are two examples of data conformity:
The order date below is expected to follow ‘MM/DD/YYYY’ format. For humans, the data in the table looks correct but for the computer data format changes will cause chaos.
Data Format conformity issues can be usually identified with the help of regular expressions.
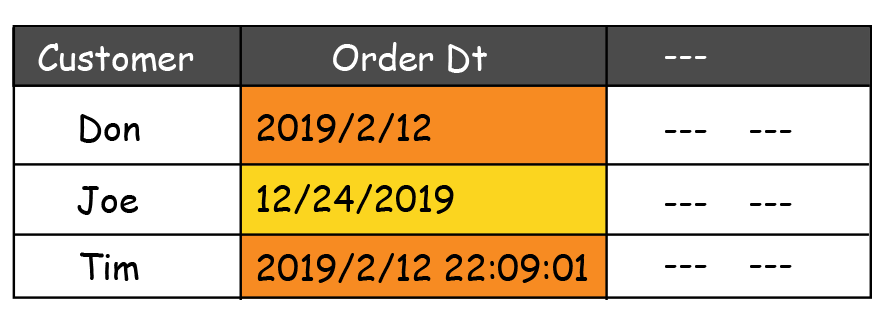
The data type is also another case of conformity quality issue. The order amount in the table below is expected to be in numeric format. But the record for Joe is written in alpha numeric format. Which is data type conformity issue.

Data Integrity Quality dimension is the degree to which a defined relational constraint is implemented between two data sets.
The data integrity issues can exist in a single system or across two systems. The main characteristic for integrity data quality dimension is the relationship between two datasets.
Here are two examples for data integrity dimension
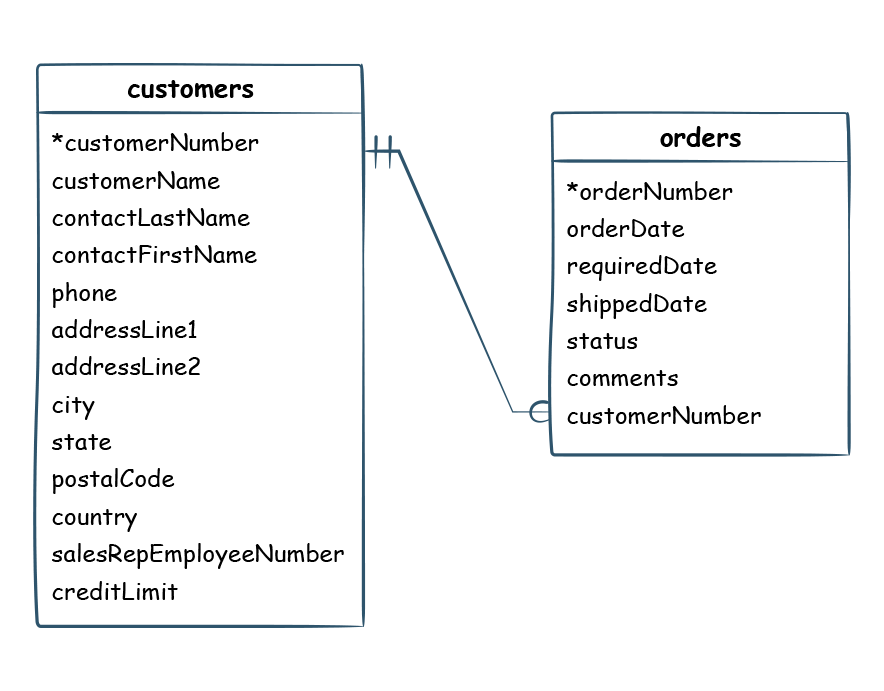
The reference for parent must always exist in a child dataset. The order has a customer number as a foreign key, then customer number must also exist in the customer table. The master dataset could be in the same database or a different system.
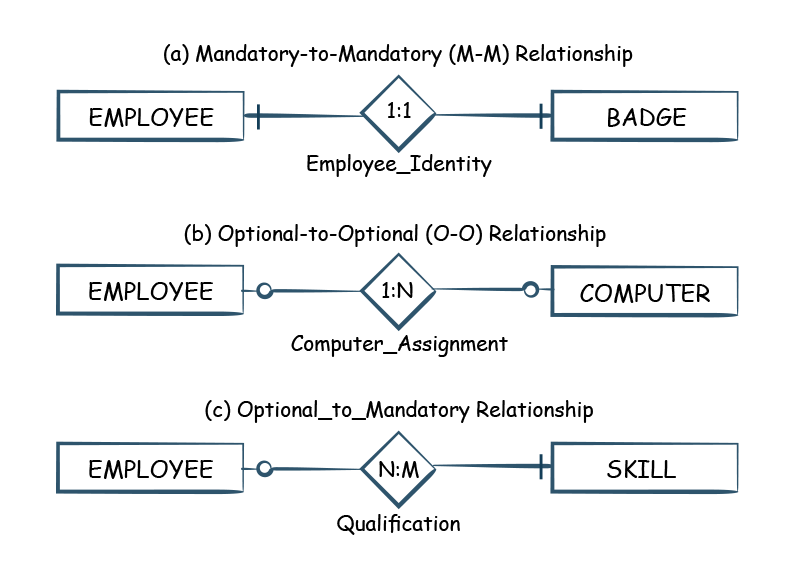
Another example of Integrity data quality dimension is Cardinality, 1:1, 1: Many, etc. Cardinality defines the ratio between two datasets. For example, an employee can only have one badge (1:1). If the cardinality of the relationship is known in advance, then it can be checked under data integrity DQ dimension.
The degree to which the data has been rounded or aggregated.
In industrial measurements precision and accuracy are different concepts. Accuracy is the deviation of from target data value, while precision is about closeness among values. Precision in data quality measurement is more of a derived concept devised to check for rounding and aggregate errors in data.
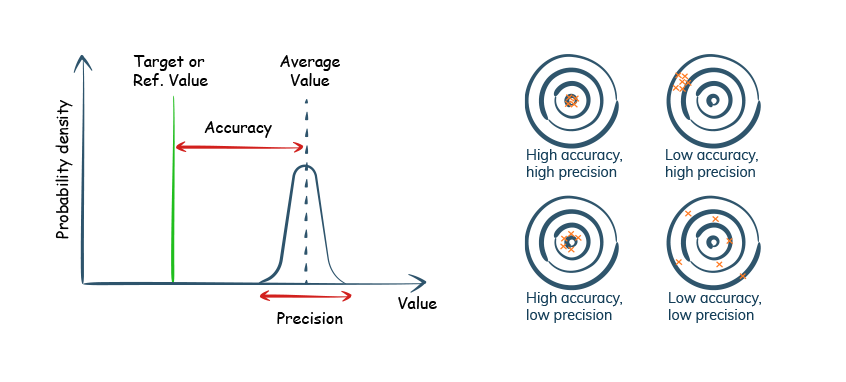
Below are some of the examples of precision errors
Depending on the degree of precision the provided by the GPS coordinates the location might differ by kilometers. The table below shows values from the two-digit precision to five-digit precision. The location error can be from 1 meter to 1 kilometer.
| GPS Decimal Places | Decimal Degrees | N/S or E/W at equator |
| 2 | 0.01 | 1.1132 km |
| 3 | 0.001 | 111.32 m |
| 4 | 0.0001 | 11.132 m |
| 5 | 0.00001 | 1.1132 m |

Imagine the consequences of military bombing 1 km away from the intended location.
For stock trading the SEC under the rule 612 has mandated a minimum precision stocks worth over $1.00 to be $0.01 and those under $1.00 stock quite needs a precision of $0.0001.
| Stock | Date | End of day Price |
| IBM | 05/05/2020 | $122.58 |
| JPM | 05/05/2020 | $92.00 |
| MTNB (Penny Stock) | 05/05/2020 | $0.7064 |
The store accounting is done at the day level and might not care for the exact second of purchase. But, for credit card fraud the time precision must be precise to the second.

Every time data is aggregated it loses details or precision. You cannot derive granular data from summarized data.
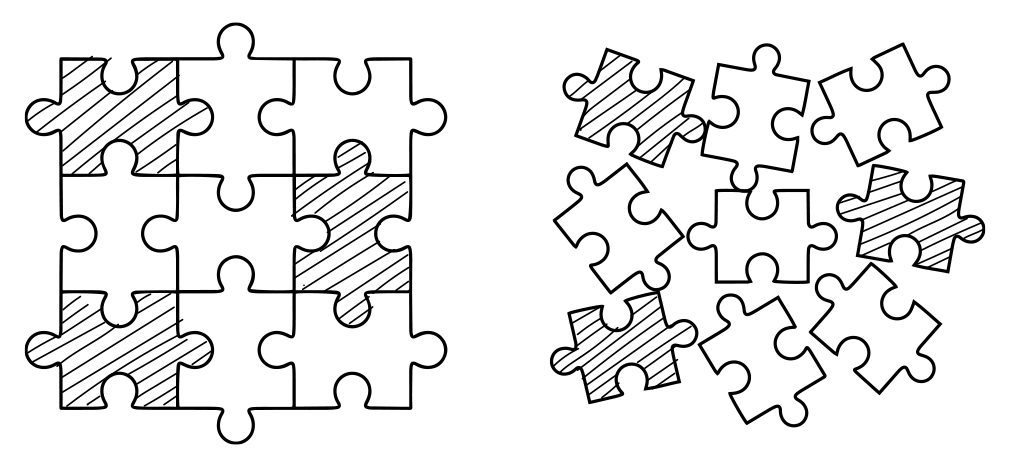
At first glance, granularity does not seem like an obvious case of precision. For some operations aggregated or summarized data is not useful.
If you want to pay each salesperson’s commission based on his personal sale, you will need his individual sales number.
| Commission Calculator | |||
| Product | $ Sales by each Employee | Commission | $ Sale by Emp X Commission % =Commission Amount |
| John Dove | — | 3% | ? |
| Evan Gardner | — | 3% | ? |
| Accessories | — | 3% | ? |
There are two fundamental ways of measuring and reporting data quality issues
This is simply the ratio of total records available to the defective records found by one of the data quality dimensions.
| Data Quality Dimension | Measurement |
| Accuracy | # Of records with inaccurate data / total # of records |
| Completeness | # Of records with incomplete data / total # of records |
| Timeliness | # Of records with Timeliness data / total # of records |
| Currency | # Of records with Currency data / total # of records |
| Consistency | # Of records with inconsistency data / total # of records |
| Uniqueness | # Of non-unique records / total # of records |
| Validity | # Of records with invalid data / total # of records |
| Conformity | # Of records with unconfirmed data / total # of records |
| Integrity | # Of records with integrity issues data / total # of records |
| Precision | # Of records with imprecision data / total # of records |
The above is easily represented by a gauge representation in a dashboard. It is also easy to aggregate or drilled down to different dimensions.
To measure data quality, we need to borrow the concept of six sigma quality from manufacturing. In simple terms, it is a ratio of opportunities to do mistakes vs. actual mistakes done.
Thus, evaluating how many products (records) you delivered defect free, compared to how many opportunities you had will provide your sigma rating for data quality.
| With data, the product we deliver is an instance of a record. We can refer to a data record as a unit product. A table is nothing but a type of unit. All | Total Units (Total Records) | 10,000 |
| With data, the product we deliver is an instance of a record. We can refer a data record as a unit product. A table is nothing but a type of unit. All the records delivered during a period are the total units. |
| Sigma level | Defects per Million (records) | Yield (records with no defects) |
| 6 | 3.4 | 99.99966% |
| 5 | 230 | 99.977% |
| 4 | 6,210 | 99.38% |
| 3 | 66,800 | 93.32% |
| 2 | 308,000 | 69.15% |
| 1 | 690,000 | 30.85% |
I hope you liked the data quality examples and understand that there is much more than the 6 DQ dimensions. Do not fret too much about these classifications, choose the one you like or define your own.
Do you agree with our thought process? Leave a comment below!

CTO and Founder at iceDQ.
First to introduce automated data testing. Advocate for data reliability engineering.
Explore the
#1 Data Testing Tool

Sandesh Gawande is the CTO at iceDQ (Torana Inc.) and a serial entrepreneur. Since 1996 Sandesh has been designing products and doing data engineering. He has developed and trademarked a framework for data integration - ETL Interface Architecture®. He consulted various Insurance, Banking, and Healthcare. He realized, while companies were investing millions of dollars in their data projects, they were not testing their data pipelines. This caused project delays, huge labor costs, and expensive production fixes. Herein lies the genesis of the iceDQ platform.


Headquarters: 60 Long Ridge Road, Suite 303, Stamford CT 06902. Phone: (203) 666-4442 Email: [email protected]
Follow us on Torana Inc. © 2024. All Rights Reserved Manage ConsentTo provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional Functional Always activeThe technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences PreferencesThe technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics StatisticsThe technical storage or access that is used exclusively for statistical purposes. The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing MarketingThe technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.